About
Segram is a software implementation of a framework for automated semantics-oriented grammatical analysis of text data. It is implemented in Python and based on the excellent spacy package, which is used to solve core NLP tasks such as tokenization, lemmatization, dependency parsing and coreference resolution.
Note
This project is still in an early stage of development, so one should expect significant changes in the future, including backward incompatible ones. That said, the general concepts and design principles should remain the same or be extended, not changed or limited. Thus, the package is suitable for experimental usage.
Main use cases and features
Automated grammatical analysis in terms of phrases/clauses focused on detecting actions as well as subjects and objects of those actions.
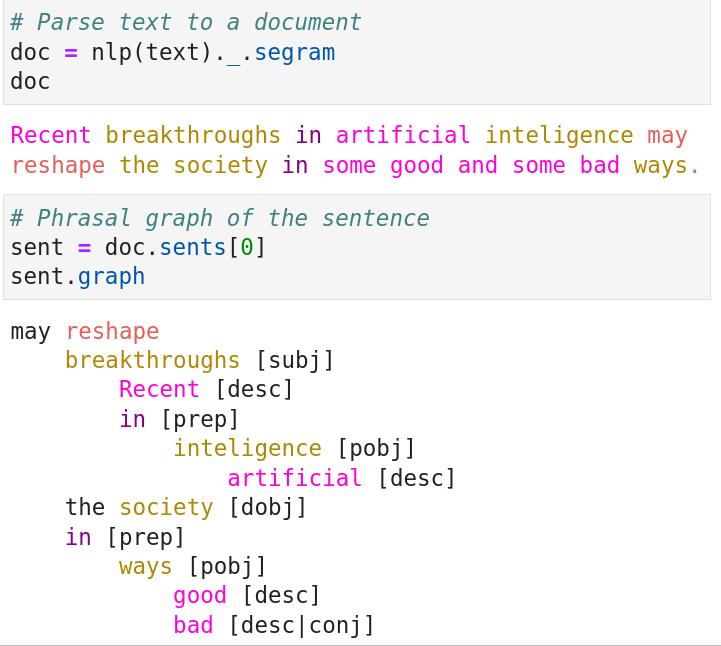
Flexible filtering and matching with queries expressible in terms of properties of subjects, verbs, objects, prepositions and descriptions applicable at the levels of individual phrases and entire sentences.
Semantic-oriented organization of analyses in terms of stories and frames.
Data serialization framework allowing for reconstructing all segram data after an initial parsing without access to any spacy language model.
Structured vector similarity model based on weighted averages of cosine similarities between different components of phrases/sentences (several algorithms based on somewhat different notions of what it means for sentences or phrases to be similar are available).
Structured vector similarity model for comparing documents in terms of sequentially shifting semantics.
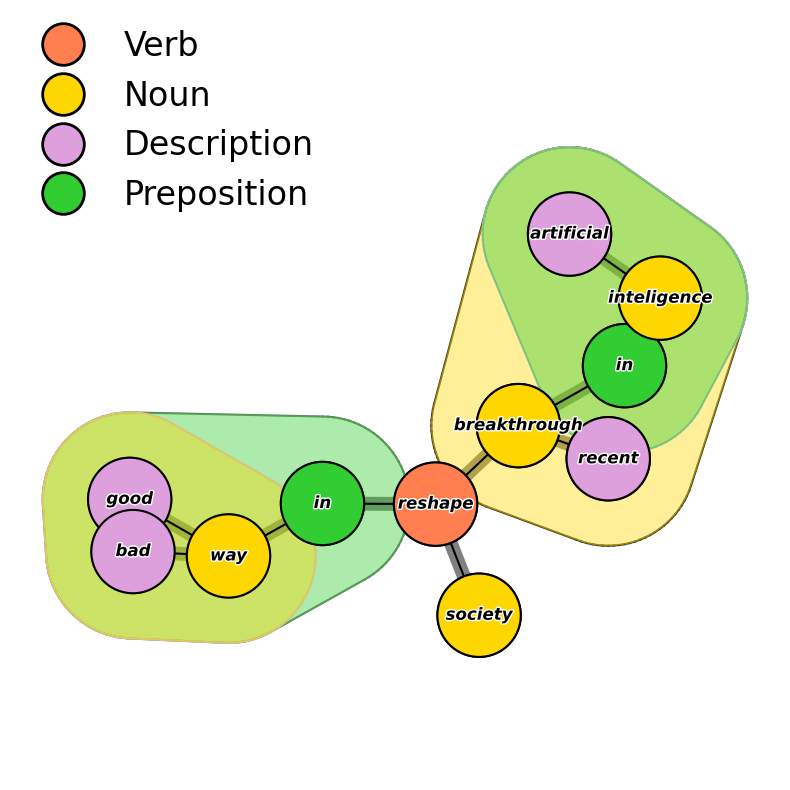
Hypergraphical representation of grammatical structure of sentences.
Note
Since segram is to a significant degree based on spacy and its design philosophy, it is recommended to have at least a basic level of familiarity with it (or other similar NLP libraries).