About
Segram is a software implementation of a framework for automated semantics-oriented grammatical analysis of text data. It is implemented in Python and based on the excellent spacy package, which is used to solve core NLP tasks such as tokenization, lemmatization, dependency parsing and coreference resolution.
Note
This project is still in an early stage of development, so one should expect significant changes in the future, including backward incompatible ones. That said, the general concepts and design principles should remain the same or be extended, not changed or limited. Thus, the package is suitable for experimental usage.
Main use cases and features
Automated grammatical analysis in terms of phrases/clauses focused on detecting actions as well as subjects and objects of those actions.
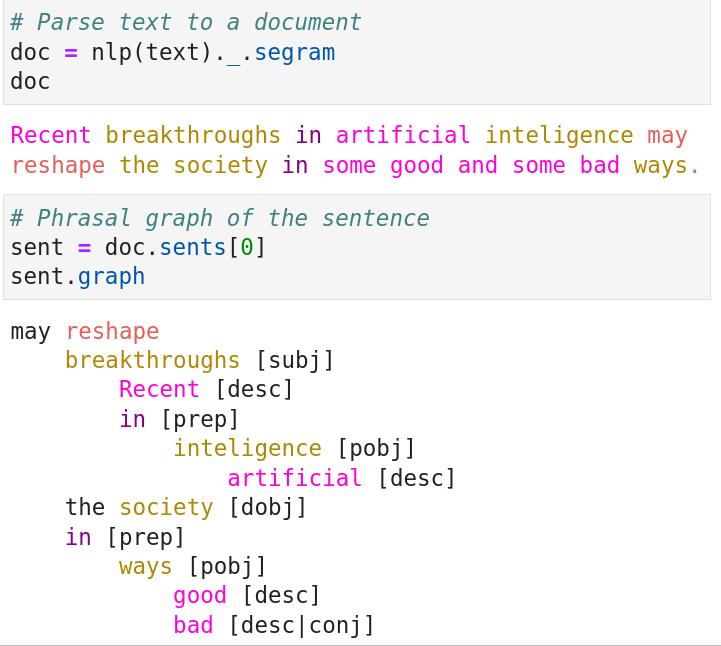
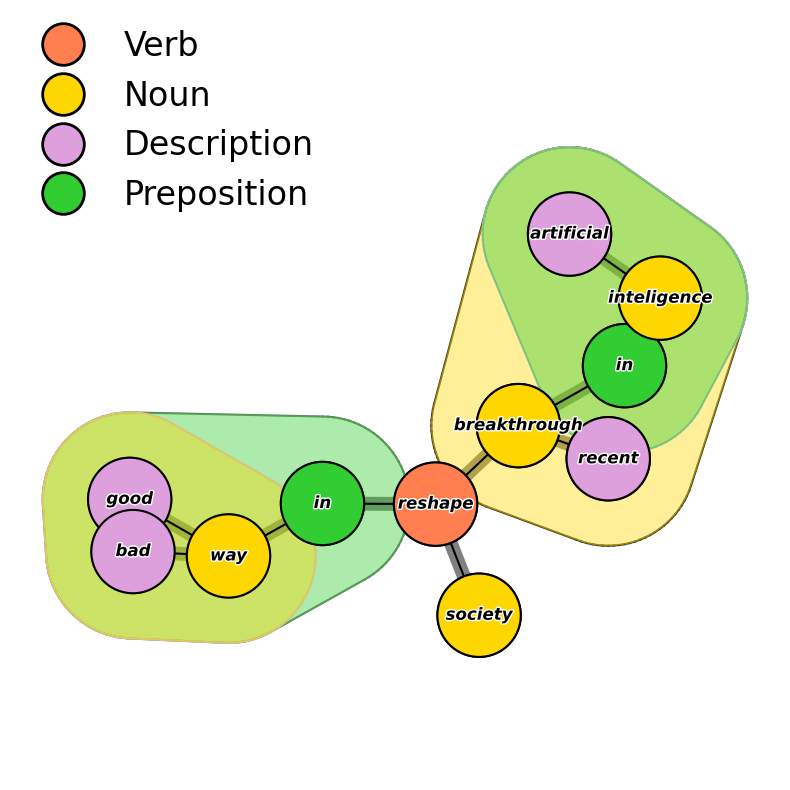
Flexible filtering and matching with queries expressible in terms of properties of subjects, verbs, objects, prepositions and descriptions applicable at the levels of individual phrases and entire sentences.
Semantic-oriented organization of analyses in terms of stories and frames.
Data serialization framework allowing for reconstructing all segram data after an initial parsing without access to any spacy language model.
Structured vector similarity model based on weighted averages of cosine similarities between different components of phrases/sentences (several algorithms based on somewhat different notions of what it means for sentences or phrases to be similar are available).
Structured vector similarity model for comparing documents in terms of sequentially shifting semantics.
Hypergraphical representation of grammatical structure of sentences.
Note
Since segram is to a significant degree based on spacy and its design philosophy, it is recommended to have at least a basic level of familiarity with it (or other similar NLP libraries).
Installation
At the command line via pip:
pip install segram
# with CUDA GPU support
pip install segram[gpu]
# with experimental coreference resolution module
pip install segram[coref]
# with both
pip install segram[gpu,coref]
Development version
The current development version can be installed directly from the Github repo
pip install "segram @ git+ssh://git@github.com/sztal/segram.git"
# with CUDA GPU support
pip install "segram[gpu] @ git+ssh://git@github.com/sztal/segram.git"
# with experimental coreference resolution module
pip install "segram[coref] @ git+ssh://git@github.com/sztal/segram.git"
# with both
pip install "segram[gpu,coref] @ git+ssh://git@github.com/sztal/segram.git"
Requirements
Package |
Version |
|---|---|
python |
>=3.11 |
spacy |
>=3.4 |
The required Python version will not change in the future releases for the foreseeable future, so before the package becomes fully mature the dependency on python>=3.11 will not be too demanding (although it may be bumped to >=3.12 as the new release is expected soon as of time of writing - 29.09.2023).
Coreference resolution
Segram comes with a coreference resolution component based on an experimental model provided by spacy-experimental package. However, both at the level of segram and spacy this is currently an experimental feature, which comes with a significant price tag attached. Namely, the acceptable spacy version is significantly limited (see the table below). However, as spacy-experimental gets integrated in the spacy core in the future, these constraints will be relaxed.
Package |
Version |
|---|---|
spacy |
>=3.4,<3.5 |
spacy-experimental |
0.6.3 |
en_coreference_web_trf |
3.4.0a2 |
Supported languages and models
Since segram is based on spacy as its engine for solving core NLP tasks, in order to do any work one needs to download and install appropriate language models.
English
Currently only English is supported and the recommended models are:
en_core_web_trf
Main English model based on the transformer architecture. It should be used as the main model for best results.
en_core_web_lg
Word vector model. The transformer model is powerful, but it does not provide static word vectors, but only context-dependent vectors. Several methods implemented in segram require context-free word vectors, so they must be obatined from a different model.
en_coreference_web_trf
Coreference resolution model. This is a separate model trained for solving the coreference resolution task. Importantly, it has to be in a version consistent with the requirements specified in the table Core requirements (coreference resolution).
Once spacy is installed, the three language models can be downloaded and installed quite easily:
# Core model based on the trasnformer architecture
python -m spacy download en_core_web_trf
# Mode for word vectors (can be skipped if vector similarity methods are not needed)
python -m spacy download en_core_web_lg # skip if word vectors are not needed
# Coreference resolution model
pip install https://github.com/explosion/spacy-experimental/releases/download/v0.6.1/en_coreference_web_trf-3.4.0a2-py3-none-any.whl
Contributing
Contributions are welcome, and they are greatly appreciated! Every little bit helps, and credit will always be given. If you want to contribute to this project, please make sure to read the contributing guideliens.
Here are some concrete ways you can help:
Reqest a new feature or report a bug by raising a new issue.
Create a Pull Request (PR) to address an open issue or add a new feature.
License
This project is licensed under the MIT License.
Copyright (C) 2023 Szymon Talaga